Essential AI Glossary
9/24/2025 • 9 min read
There are lots of "AI glossaries" out there, but this one is designed to give you what you need to know, and cut out the rest.
One of the biggest challenges for leaders trying to understand AI is figuring out the difference between what's important and what's not. I've seen glossaries include things which are total hype, or pure theory.
This glossary includes what you need to know, and nothing more.
Models
Definition: Models are mathematical functions that predict some output, given an input.
Models are the core of all AI systems. They take in an input (like your message to ChatGPT), transform it, and give you an output (like the response to your message).
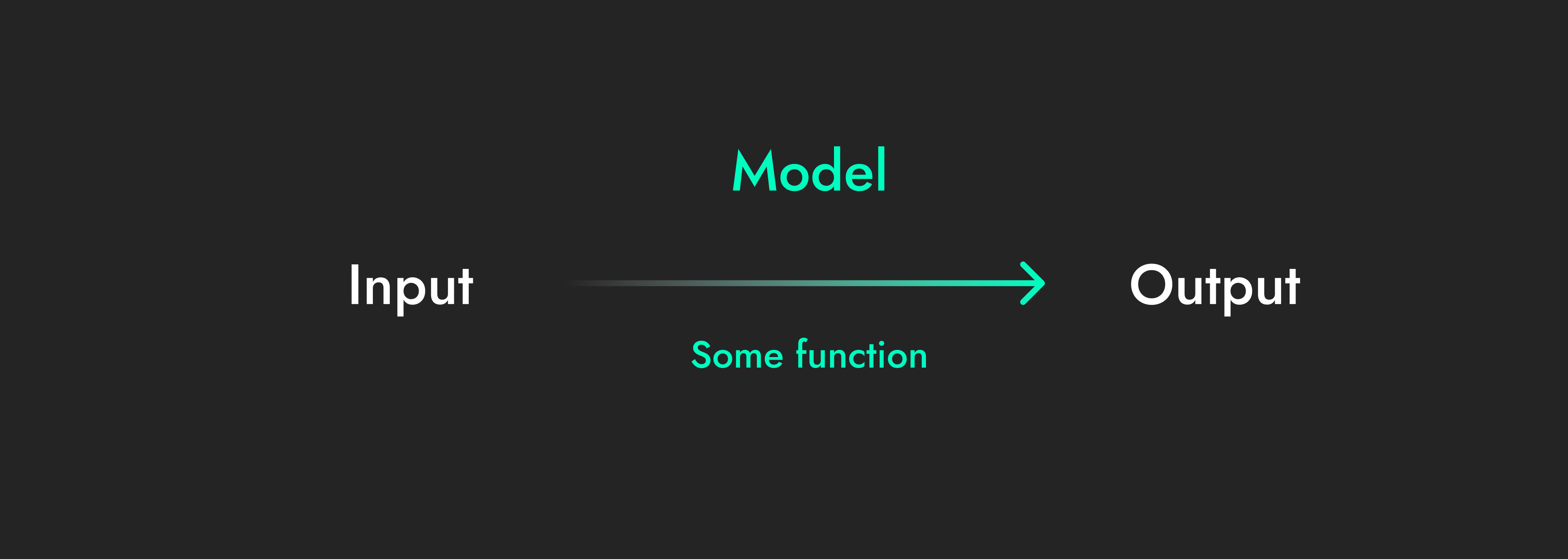
All models look like this:
Examples:
gpt-3.5Is a model that can take in text requests and output text responses.- AlexNet is a model that can take in images and output a classification as one of many labels (e.g. input: image of a plane → output: “plane”).
- You might have a mathematical model that predicts the amount of CO2 output by a factory given the state of all the machines.
- An AI model in a self driving car would predict the desired acceleration and steering direction as an output, given the video seen by the car’s cameras as an input.
- Sesame is an AI model that turns input text into human-like speech audio as output.
Now I hope I’ve got you wondering “what does a model look like on the inside?”
Parameters
Under the hood, every model is a mathematical equation. They take your input (e.g a text request + a file + an image) and turn it into numbers, then perform a mathematical calculation/transformation on it, and respond with numbers as an output, then these are turned back into a useful format (e.g. text response).
A ridiculously simple possible model might be:
is the output prediction, is the input, and 2 & 3 are parameters that control how the input is transformed to give you an output.
But you can also have MUCH more complicated models, that do something much more complicated to the input, which have many more parameters.
Here’s a diagram of a bigger model (although still TINY compared to todays standards):

Every line represents some calculation with parameters. The equation that this model uses to turn and input into an output has a few thousands of parameters is far too long for me to write out here, but more importantly, it’s not important to even think about the equations! What’s important to understand is that 1) all models are math and 2) the parameters control how good the model is at giving us useful outputs.
Most household model names like gpt-4o or claude-sonnet-3.5 have billions to trillions of parameters.
When people talk about “bigger models” they mean models with more parameters.
Examples:
llama3-70bIs a model with 70 billion parameters.- “We fine-tuned the parameters so that the model performs better on healthcare-related problems”.
- “It’s taking weeks to train the model because it has 1 trillion parameters”.
- “You can’t run this model on a mobile device because it doesn’t have enough memory to store all the parameters”.
The next question is “how do we find the right parameters for a model?”
Training
Training is the process of finding the function that gives you the output you want from the input you provide
Or in more technical language: Training is the process of finding the parameters of a good model.
Here’s the high level of what you need to know about how training an AI model works.
- Initialise a model with random parameters.
- Show it some example inputs it should predict outputs for.
- Tell it how bad its predictions were for those examples.
- Move the parameters slightly in a direction that would have made it less bad.
- Repeat steps 2-4 many millions of times until the model stops getting better or achieves sufficient performance.
Whilst training a model it’s useful to visualise how bad its doing over time. “Loss” is a measure of how bad the predictions are during training. As the model sees more examples, it updates its parameters, learning from that experience, and makes better predictions.
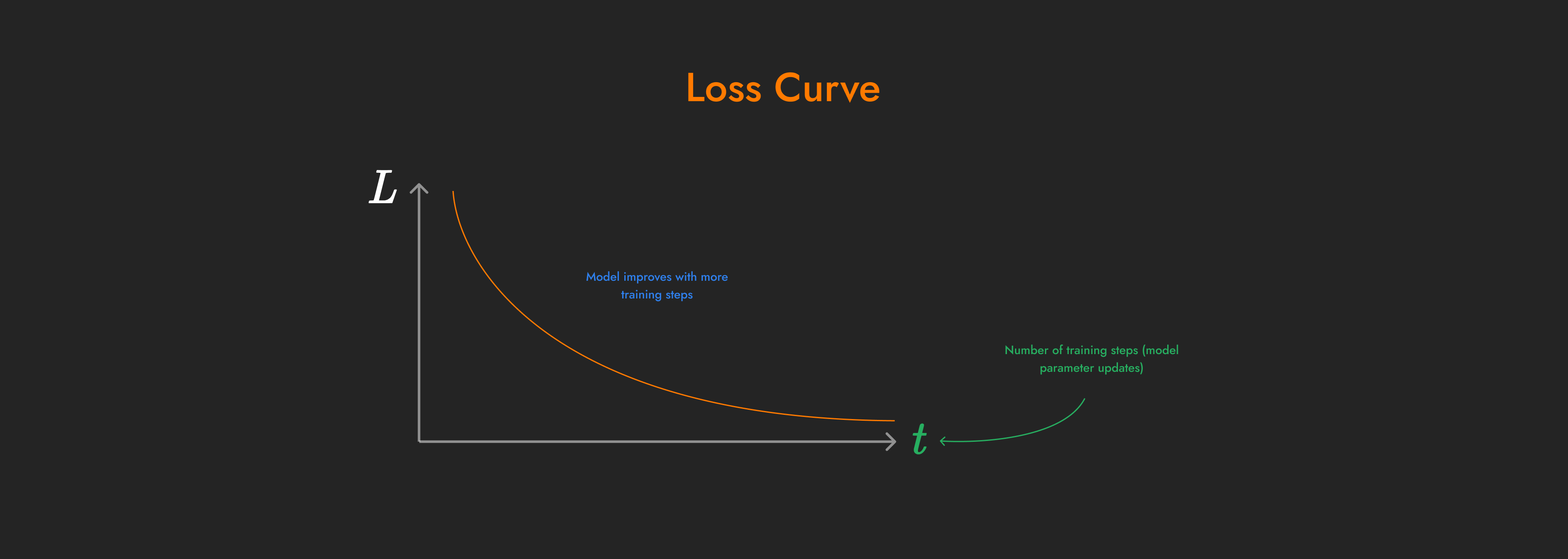
An example loss curve shown over time during model training
Training a model can be massively accelerated by using a GPU (graphics processing unit). This is because GPUs can run calculations in parallel, allowing you to do things like show the model 64 different examples at once instead of sequentially during each training step or process different parts of an input image at the same time.
Machine Learning
Machine learning (ML) is an approach to AI where the software learns to perform a task using the data as experience
This is opposed to other AI systems that might follow things like expert rules (e.g. HOG) or heuristics (e.g. A* search). They’re all AI, because they’re performing tasks without following step by step instructions, but only machine learning if they figure out what to do from the data.
Neural Networks
Neural networks are a type of model capable of representing any input → output relationship
The key characteristic of neural networks is that they are “general function approximators”. Whatever the incredibly complex relationship between the inputs and outputs in your dataset, neural networks can learn to perform the mapping between them!
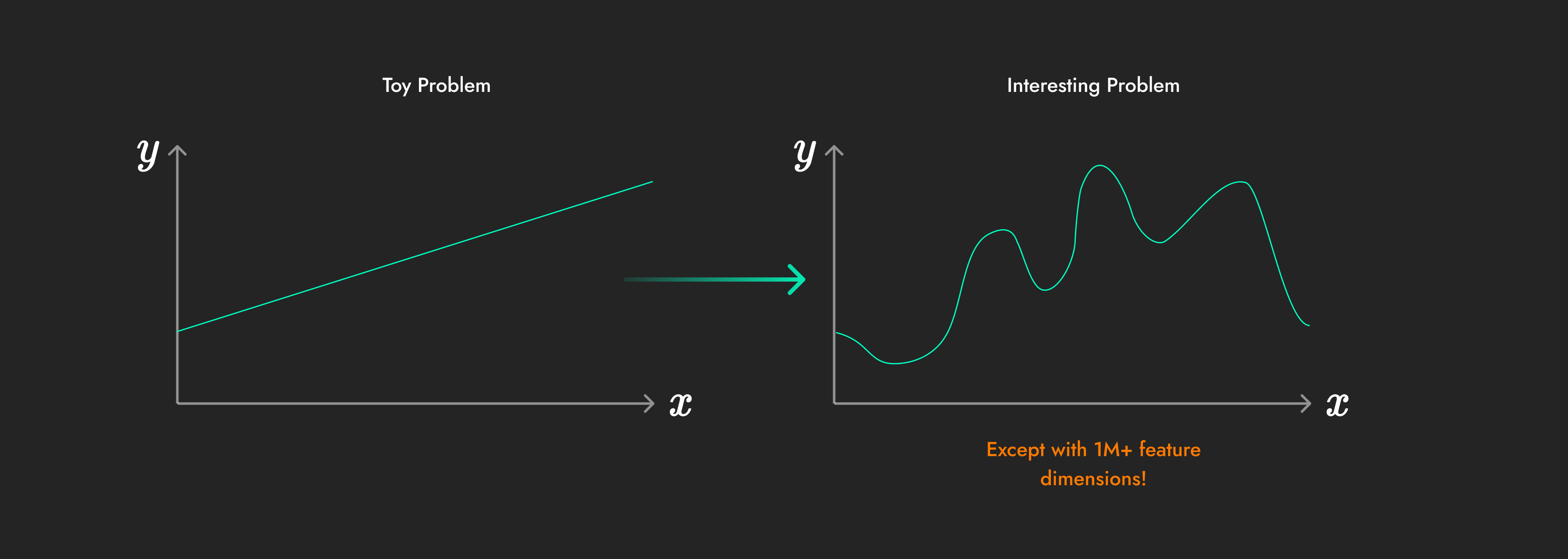
No matter how complicated the relationship, a neural network can represent it!
For example, the same neural network
All the most sophisticated AI systems we use today have types of neural networks as their underlying model.
Examples:
- The T in GPT stands for Transformer, which is a type of neural network used as the backbone for all GPTs, Llama, Qwen, Falcon, Mistral, etc.
- CNNs (convolutional neural networks) are types of neural networks that work well for processing spatial information like images and video.
You could have two neural networks that have different parameters, or you could have two neural networks with totally different architectures. The architecture defines what types of mathematical squashing and stretching happen in what order. The most fundamental types of neural network architecture changes would be changing the number of layers (the depth) or changing the width of those layers, or using different mathematical functions in different layers (e.g. convolutional layers instead of linear layers).
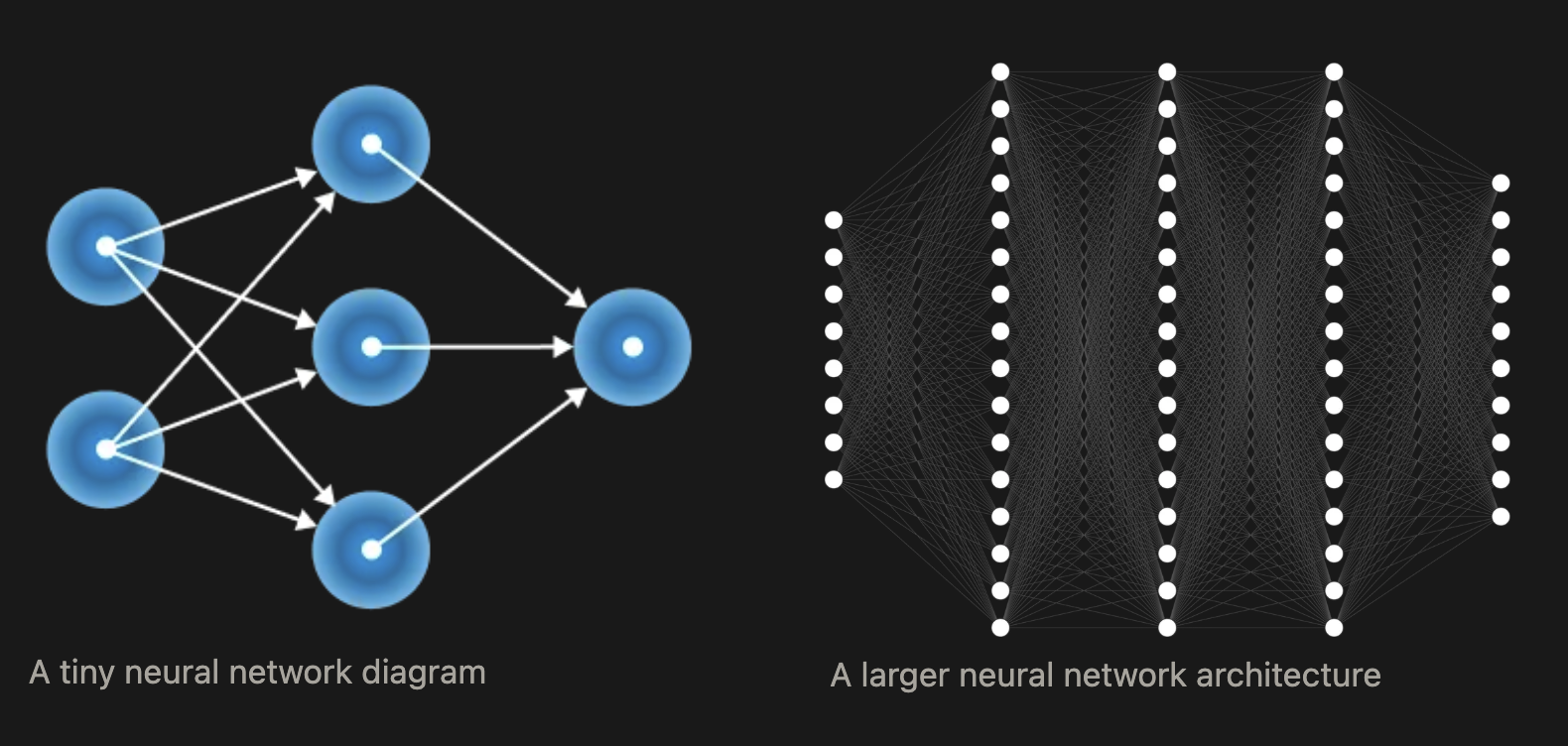
A larger neural network architecture
Examples:
- “The new neural network is designed to process bigger input images, so it has a wider input layer”.
- “AlexNet is an 8 layer convolutional neural network”.
- “We saw step-change improvement in language modelling when the transformer architecture was invented”.
Deep Learning
Deep learning is an approach to machine learning where neural networks are used as the model
Neural networks don’t just apply one transformation to the input, they apply many one after another! Neural networks repeatedly squish and stretch the input layer after layer. The later calculations are applied in “deeper” layers in the model, which is where the term “deep learning” comes from.
Training Vs Production/Inference/Deployment
AI models are in one of two distinct modes: training or production
- Training: when the model is figuring out how to make good predictions.
- Production: when the model’s predictions are sent to customers to solve real problems.
During training, the AI is just running on it’s provider’s datacenter computers, repeatedly making predictions, and learning how to improve them. The outputs it generates are thrown away.
“Moving a model to production” or “deploying a model” means taking the trained model, locking its parameters in place, exposing it to real customers, and allowing them to ask the model to provide outputs to real inputs.
Inference is a scientific word that has been abused by engineers and companies. Technically, it just means making a prediction (kind of). But when people say “inference” they mean using a model to make predictions for some real data.
Examples:
- During training, the model’s predictions are only used to tell it how to do better next time.
- During training, the model is not sending predictions to customers.
- During deployment, the models predictions might be shown to the user to answer a question.
When OpenAI or any model provider releases a new model (e.g. “today we released gpt-4.1-nano!”), they’re allowing customers to send requests to that new model architecture which will be turned into outputs computed by the model's new parameters. They may have changed the structure of the model (e.g. made the architecture deeper etc) and have almost certainly set new parameters.
Large Language Models (LLMs)
Language models output text
Large language models are just big neural networks that output text. They’re large when they have billions of parameters. There’s no scientific definition for what’s large and what’s not. You may also hear of SLMs (small language models) which are just language models that are small enough to run quickly or on limited-memory devices like phones.
Multimodal Models
Multimodal models can understand and process different types of data at the same time (text, voice, image, video)
Examples:
gpt-4oIs a multimodal model that can understand images and text and more.
GenAI
GenAI (generative AI) is the category of models that generate data that looks like the data they were trained on e.g. text / images / video.
GenAI examples:
- Language models are genAI because they generate text like the text they were trained on.
- Image generators are genAI because they generate images like those they were trained on.
- Forecasting models could be classified as genAI, because they generate trends of data in the same format as what they’ve been trained on, but they’re not typically what pundits mean when they make claims about the capabilities of “genAI”.
Reasoning Models
Reasoning models “think” before they respond, by having an internal conversation with themselves.
You may have used some models that show a “thinking” spinner or let you see the thought process that the model is going through. By “thinking through their steps”, models seem to be able to achieve better answers or handle tougher problems.
Because they take time to generate an internal monologue before responding, reasoning models take longer to respond, and use more compute. We describe thema s benefitting from “test time compute” (additional computing power used during production, not training).
Agents
Agents do long-running work in the background
Agents do the following:
- Use a language model to generate a chain of thought about how to tackle a problem.
- Make use of tools like web search or integrations with your email, database, etc.
- Pass the results of these tool calls (web search results, unread emails, database queries) back to a language model to generate the next steps.
Examples:
- ChatGPTs “agent mode” can.
- Go and perform hours worth of research in the background before coming back to you with a final report.
- Open up its own Linux computer environment running on OpenAI’s servers and spend and an hour creating you a presentation or spreadsheet.
- OpenAI Codex is a software engineering agent that can implement features in your codebase overnight before returning to you with a request to merge its changes.
- AI sales agents can autonomously use a CRM, call customers, and update notes 24/7.
Agents are not models, they are an application of language models.